为什么机器阅读理解模型学到推理捷径
2021.10.19 15:09浏览量:374简介:文字干货分享
最近,许多机器阅读理解 (MRC) 模型汇报了接近甚至优于人类的表现。然而,现有的工作表明,这些模型可能只是学会利用一些推理捷径,而并没有真实地超过人类。在这项工作中,我们试图探索为什么这些模型学习到了这些捷径,而不是数据集中预先设置的推理技能。我们认为,训练数据中较大比例的捷径问题使模型过度依赖捷径技巧。为了验证这一假设,我们设计了两个人工数据集,其中每个问题均有两个版本:可以通过推理捷径解答或不能通过推理捷径解答。我们也提出了两种方法来定量分析关于推理捷径和推理挑战的学习难度。实验结果表明,MRC模型往往更早地学习捷径问题,而训练集中可用推理捷径解答的问题比例过高阻碍了模型在训练后期进一步探索复杂的推理挑战。
本期AI TIME PhD直播间,我们有幸邀请到了这项工作的作者来雨轩博士为大家分享这项研究工作!
嘉宾介绍
来雨轩
北京大学博士
研究兴趣为自然语言处理,主要包括自然语言问答,预训练语言模型等。在ACL、AAAI、IJCAI、NAACL等自然语言处理及人工智能领域学术会议上发表论文十余篇。十余次担任ACL、AAAI、IJCAI、EMNLP、COLING、NAACL等国际著名学术会议的程序委员会委员,并获得杰出审稿人等称号。
01 相关背景
机器阅读理解的任务是给模型一篇文章和一个问题,当模型读完问题之后,给出答案,目前针对这一研究的处理方式得到的答案是问题的连续字串。
比如左图所示文章段落和问题,
问题:什么导致降水量下降?
答案:gravity。
存在挑战:
- l 具有底层自然语言处理的能力;
- l 检索到相关证据;
- l 涉及到世界知识。

02 推理捷径
(1) 疑问词匹配方法
人在阅读时会根据问题中提到scholastic journal和come out找到one-page journal和Begun这种目标信息。而机器会直接定位到更简单的词汇“When”,然后找到对应答案“September 1876”。

(2)简单字面匹配方法
人会根据语法结构进行判断,而机器会根据简单的字面匹配进行推理,比如定位到与问题中相同的词汇rated…as,找到答案Beyonce。
总的来说,模型会利用小的技巧或局部证据得到答案,并没有关注问题和文章中所有关键的组件。这会导致所得答案的不可靠性增强,如果例一中有两个时间出现,或者例二中有两个相似的词出现,那就会导致错误答案。
两个局限:
(1)导致输入的扰动非常敏感;在文章后面赘述了一句和问题非常相似的语句,指使修改了关键信息,指向了错误答案,所以很多模型找到的都是错误答案。
(2)对问题和文章的修改不敏感;当把文章和问题修改的面目全非后,所得到的答案仍然没有改变。
03 问题假设
是不是训练集当中见到了越多的推理捷径的问题,在模型学习之后模型就会更倾向于使用的推挤捷径的技巧进行解题?
04 实验验证
4.1 构建数据集
首先,控制训练集中推理捷径的比例。为了更好的做对比试验进行控制变量,设计了人造数据集,数据集中每一个样例都有两个版本。版本一是通过推理捷径就可以解决的,在shortcut version中,包含刚刚两个例子中的两种模式;另一个版本是challenging version,都使用统一复述(paraphrasing)的方式。构建数据集方式如下图所示。

4.2 实验结果
如果所有训练集都用challenging版本,那么在shortcut版本中推理捷径问题的比例是1:0。当从challenging 版本换成shortcut版本时,那么推理捷径问题的比例将上升到10%-20%。当采用测试集进行测试时,可以观察模型在推理捷径版本的问题上的性能表现和只能用paraphrasing技巧解决测试集表现的差距,进而比较模型有多大程度上依赖推理捷径。因为推理捷径问题既可以通过推理捷径来解决,也可以通过paraphrasing技巧解决,而具有推理挑战的问题,其困难版本测试集只能通过paraphrasing技巧解决,所以shortcut version模型能够在取得更好的性质,一定是因为它依赖了推理捷径技巧来解题。
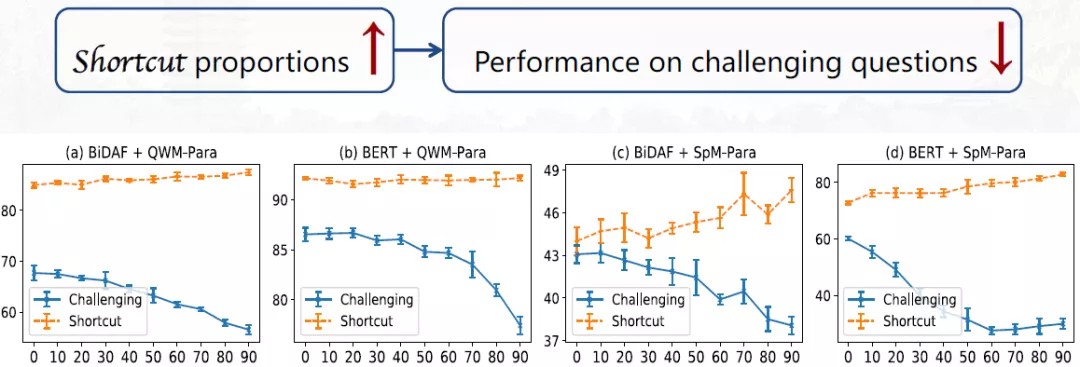
从上图可以看出,通过进行控制变量的实验,在训练集中提升了推理捷径的比例,模型在challenging版本中的性能是有非常明显的下降的,从而模型在推理捷径问题和具有挑战的问题之间的差异提升了,表明模型更依赖于推理捷径的技巧来解题。
思考:
为什么模型在混合的情况下,还会继续学习推理捷径技巧来解决问题。是否因为推理捷径问题比较容易,促使模型学更容易的东西,从而只引入了很低的比例,就会把模型带偏呢?
所以接下来,我们试图衡量推理捷径问题的难度,是否比具有挑战的问题更容易。通过如下两种方式进行衡量(如下图所示):(1)更容易的问题需要更少的步数进行拟合;(2)更容易地问题需要更少的参数进行拟合。
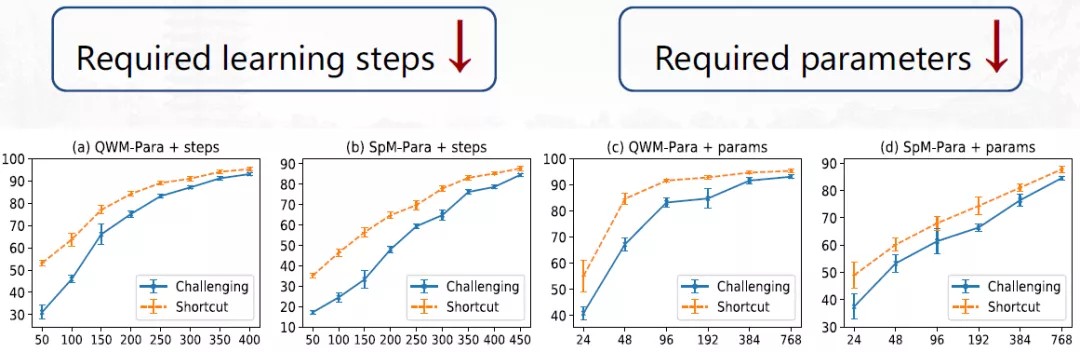
结果发现,模型在学习推理捷径问题时比学习具有挑战性问题时需要的步数更少,推理捷径问题的确比具有挑战的问题更容易学习。
需要注意的是,此部分我们采用训练集来做训练和测试,因为此时我们需要观察模型的学习能力而不是泛化能力,所以从训练集来观测模型拟合的难易程度。
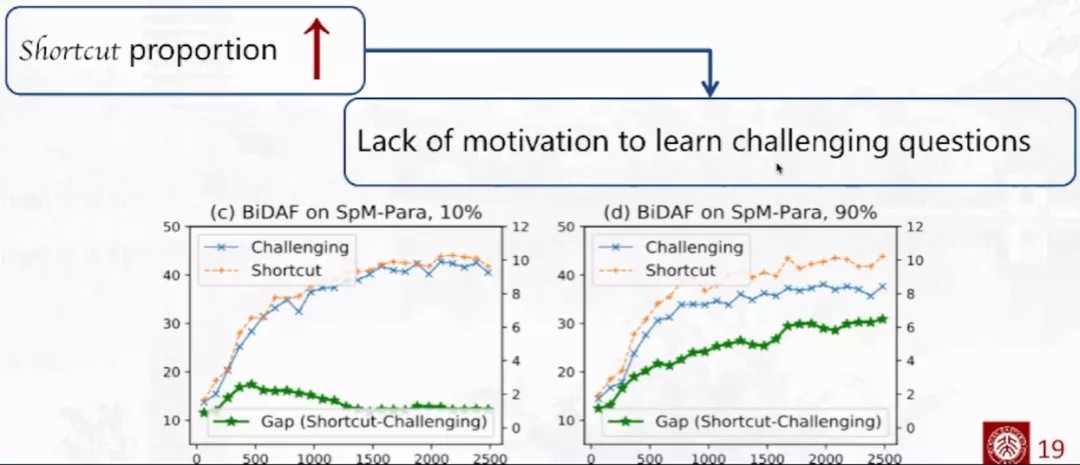
在优化时采用梯度下降的方法,该方法会选择最快的优化梯度进而最小化在训练集上的损失,针对推理捷径问题来说,它更容易,所需参数和步数更少,所以对于梯度下降优化器来说,先拟合推理捷径技巧是一个优先解,这样可以快速下降模型在训练集上的损失。
如果推理捷径问题的比例小(10%),损失下降后陷入了推理捷径技巧的局部最优之后,模型中可能还有大量的没有解决的具有推理挑战的问题,这些问题可以再把问题推出局部最优,从而图中表示Gap的绿色曲线呈现出先提升再下降的表现。如果推理捷径问题的比例高(90%),模型陷入局部最优,无法学习推理挑战问题。
05 结论
(1)推理捷径问题需要更少的训练步数和模型参数就可以解决。
(2)推理捷径技巧通常会在训练的早期被学到,而对于更多的推理捷径问题会使得模型会诱于局部最优无法跳出来,导致模型更多的依赖于推理捷径来解题,换句话说,没有学到复杂推理技巧。

发表评论
登录后可评论,请前往 登录 或 注册