智能体(AI Agent)开发实战之【LangChain】(二)结合大模型基于RAG实现本地知识库问答
2025.06.23 17:06浏览量:199简介:智能体(AI Agent)开发实战之【LangChain】(二)结合大模型基于RAG实现本地知识库问
上一篇介绍了接入大模型输出结果,实现了基本的问答功能。现有大模型都是基于公开资料训练的,搜索垂直专业领域的知识可能会出现问题。本篇文章会基于RAG实现简单的知识库问答功能。
一、RAG介绍
RAG(Retrieval Augmented Generation)即检索增强生成,是一种结合了信息检索和大语言模型(LLM)生成能力的技术,旨在解决大语言模型在回答问题时,因知识更新不及时、缺乏特定领域知识或事实性错误等问题,通过在生成回答之前检索相关外部知识源来增强回答的准确性和可靠性。
1.工作原理
检索阶段:当用户提出一个问题时,RAG 系统首先将问题发送到内部的知识源(如文档库、数据库等)进行检索。通常会使用向量检索技术,将问题和知识源中的文档都转换为向量表示,然后计算问题向量与文档向量之间的相似度,找出与问题最相关的文档段落。
生成阶段:将检索到的相关文档段落与用户的问题一起输入到大语言模型中,大语言模型结合这些外部知识生成最终的回答。
2.优势
知识更新:可以利用最新的内部知识来回答问题,避免了大语言模型因训练数据固定而导致的知识过时问题。
特定领域知识:对于特定领域的问题,能够从专业的知识源中获取相关信息,提高回答的专业性和准确性。
减少幻觉:通过引入内部知识,减少大语言模型生成回答时出现问答错误和幻觉内容。
二、具体的功能实现
1.准备知识源
选择合适的知识源,如文本文件、PDF、Word、数据库等本地或内部的结构化或非结构化数据。如我在本地准备了一个自己胡编的一段内容。
2.对知识源进行预处理,包括文本清洗、分词等
def load_and_process_documents(directory):
"""
加载并处理指定目录下的所有文本文件
:param directory: 包含文本文件的目录路径
:return: 处理后的文档块列表
"""
documents = []
# 遍历目录下的所有文件
for filename in os.listdir(directory):
if filename.endswith('.txt'):
file_path = os.path.join(directory, filename)
# 使用 TextLoader 加载文本文件
loader = TextLoader(file_path, encoding='utf-8')
loaded_docs = loader.load()
documents.extend(loaded_docs)
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每个文档块的大小
chunk_overlap=200 # 相邻文档块的重叠部分大小
)
# 分割文档
split_docs = text_splitter.split_documents(documents)
return split_docs
3.数据向量化
选择合适的向量数据库,如 FAISS、Chroma 等。我分别试了这两个数据库都是可以的。然后将预处理后的知识源文档转换为向量并存储到向量数据库中。
def create_vector_store(docs):
"""
创建向量数据库并存储文档向量
:param docs: 处理后的文档块列表
:return: 向量数据库对象
"""
# 初始化 OpenAI 嵌入模型
#embeddings = OpenAIEmbeddings()
# 使用 Chroma 创建向量数据库并存储文档向量
vectorstore = Chroma.from_documents(docs, embeddings)
# 使用 FAISS 创建向量数据库并存储文档向量
#vectorstore = FAISS.from_documents(docs, embeddings)
return vectorstore
4.创建检索并设置问答链
def setup_qa_chain(vectorstore):
"""
设置问答链
:param vectorstore: 向量数据库对象
:return: 问答链对象
"""
# 初始化 OpenAI 大语言模型
#llm = OpenAI()
llm = ChatOpenAI(
model = "Qwen/Qwen2.5-7B-Instruct",
openai_api_key=DEEPSEEK_API_KEY,
openai_api_base=DEEPSEEK_API_BASE,
temperature=0.7, # 控制生成文本的随机性
max_tokens=500, # 限制生成的最大token数
#stream=True #开启流式输出
stream=False #关闭流式输出
)
# 创建检索式问答链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 使用 "stuff" 类型将检索结果直接输入到 LLM
retriever=vectorstore.as_retriever() # 向量数据库的检索器
)
return qa_chain
5.运行代码测试功能,如下图所示: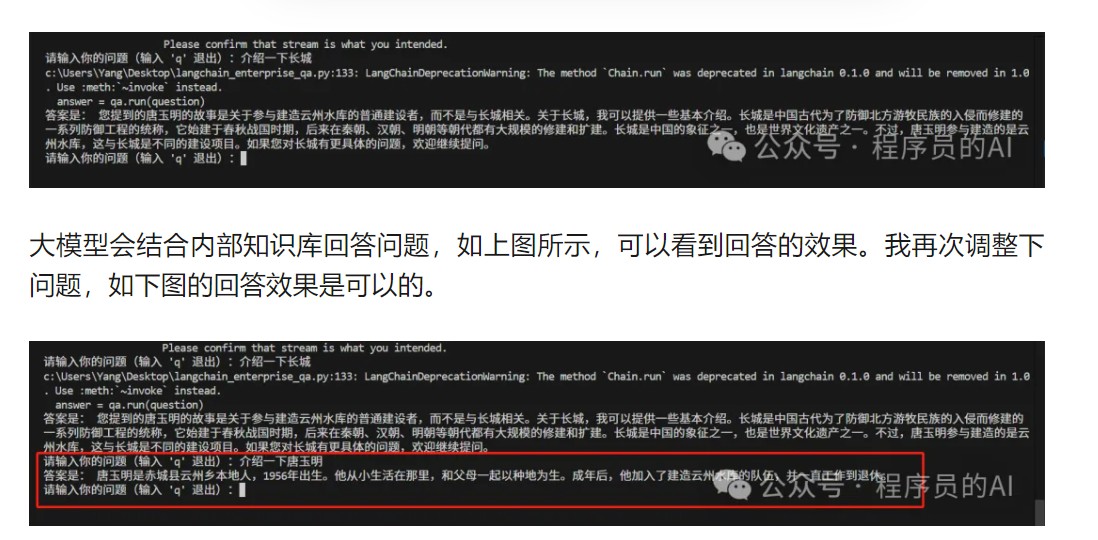
三、总结
LangChain 提供了丰富的动态扩展功能,可以基于RAG实现企业内部私有智能体。在使用RAG时也需注意数据质量或直接影响 RAG 系统的性能,需要对数据进行严格的清洗和预处理。还需选择合适的向量表示方法和嵌入模型,提高检索的准确性和企业适用场景。

发表评论
登录后可评论,请前往 登录 或 注册